Architecture Case Study: Diving in AWS Data Lake Architecture
Architecture deep dive covering ingestion, storage and governance patterns for an AWS data lake.
Quick takeaways:
- Business context explains why an enterprise data lake is needed and who it serves.
- Shows the end-to-end data lifecycle from ingestion through curation, analytics, and visualisation.
- Highlights the AWS building blocks that deliver governance, security, and reporting capabilities.
Introduction
A client organisation is initiating the development of an advanced data storage system utilizing Amazon Simple Storage Service (Amazon S3) to create a comprehensive data lake. This system will serve as the backbone for integrating various data sources and enabling sophisticated data analysis capabilities.
High Level Data Lake Storage System Requirements
Data Ingestion Requirements
-
Real-Time IoT Data Collection:
- Develop a real-time data ingestion mechanism for IoT sensor data.
- Ensure the ingestion process supports high-velocity and high-volume data streams.
-
Historical Data Integration:
- Implement a batch ingestion process for importing historical data from existing databases.
- Design the system to maintain data integrity and optimize for large-scale data transfer.
-
Third-Party Data Enrichment:
- Establish a protocol for ingesting supplemental data from third-party sources.
- Ensure compatibility and seamless integration with internal data structures.
Data Processing and Transformation Requirements
-
Data Cleaning and Transformation:
- Design a data transformation pipeline that cleanses, normalizes, and enriches the raw data.
- Utilize technologies that are compatible with Apache Hadoop ecosystems to align with current team expertise.
-
Scalable Data Processing Solutions:
- Leverage cloud-based data processing services that can scale with the growth of data volume.
- Prioritize services that offer interoperability with Hadoop-based tools and minimize the need for additional training.
Data Analysis and Visualization Requirements
-
Analytical Dashboards:
- Develop interactive dashboards that provide visual representations of data insights.
- Ensure dashboards are user-friendly and can be customized to highlight key performance indicators.
-
Advanced Analytics Integration:
- Support advanced analytics, including machine learning models compatible with current team skills.
- Facilitate seamless integration with existing reporting tools and workflows.
Data Storage Requirements
-
Cost-Effective Storage Tiers:
- Implement storage solutions offering tiered storage options to optimize costs.
- Ensure storage services provide lifecycle management policies for automated data archival.
-
Secure and Compliant Storage:
- Implement robust security controls to protect data at rest.
- Ensure compliance with data regulations relevant to the organisation�s operations.
Data Access and Governance Requirements
-
Role-Based Access Control:
- Implement fine-grained access control that aligns with organisational roles.
- Ensure data access policies are clearly defined and enforced.
-
Data Lineage and Auditing:
- Track data lineage from source to consumption to maintain transparency.
- Implement auditing capabilities to monitor data access and usage.
Data Integration Requirements
-
Integration with Source Systems:
- Ensure seamless integration with existing on-premises and cloud data sources.
- Support a variety of data formats and ingestion protocols.
-
Integration with Analytics Platforms:
- Ensure compatibility with analytics platforms and business intelligence tools.
- Provide data access via APIs or direct connectors to analytics services.
Operational Requirements
-
Monitoring and Alerting:
- Implement monitoring systems to track performance, availability, and data quality.
- Set up alerting mechanisms for potential issues in the data pipeline.
-
Disaster Recovery and Backup:
- Establish disaster recovery strategies to ensure data resilience.
- Implement automated backup solutions with defined recovery point objectives.
User Enablement Requirements
-
Accessible Documentation:
- Create documentation that outlines data catalogues and usage guidelines.
- Provide self-service access where teams can discover and request data sets.
-
Training and Support:
- Offer training sessions to onboard users to the data lake environment.
- Establish a support model for troubleshooting and best practice guidance.
Scalability and Future Growth Requirements
-
Elastic Scalability:
- Leverage services that automatically scale resources based on demand.
- Plan for future data sources as the organisation expands capabilities.
-
Ecosystem Compatibility:
- Adopt services which integrate with broader AWS ecosystems and third-party tools.
- Ensure roadmaps for chosen services align with organisational growth strategies.
Cost Management Requirements
-
Cost Transparency:
- Implement tools to track and report on data storage and processing costs.
- Provide dashboards for stakeholders to monitor usage trends.
-
Optimised Resource Utilisation:
- Adopt auto-scaling and serverless options where appropriate to optimise spend.
- Regularly review and adjust resource allocation to match workload patterns.
Stakeholder and Governance Requirements
-
Executive Reporting:
- Provide executive stakeholders with summarised dashboards and reports.
- Align data lake objectives with broader business outcomes and KPIs.
-
Governance Framework:
- Define governance processes for data access requests and approvals.
- Establish stewardship roles to oversee data quality and lifecycle management.
Compliance and Regulatory Requirements
-
Regulatory Alignment:
- Ensure the data lake complies with industry-specific regulations.
- Implement auditing capabilities to demonstrate compliance.
-
Data Retention Policies:
- Define retention and deletion policies aligned with legal requirements.
- Automate policy enforcement across the storage tiers.
Business Continuity Requirements
-
Resilience Planning:
- Design the architecture to support rapid recovery from system outages.
- Document runbooks for disaster recovery drills.
-
Support for Future Use-Cases:
- Ensure the platform can extend into predictive and prescriptive analytics.
- Provide APIs for downstream automation and workflow integration.
General Requirements
-
Cost-Effectiveness:
- Implement a solution that provides optimal cost-to-performance ratio.
- Monitor and optimize resource usage to manage operational costs.
-
Security and Compliance:
- Adhere to industry-standard security practices to protect data at rest and in transit.
- Ensure the system complies with relevant data protection regulations.
-
System Scalability and Reliability:
- Design the architecture to support scaling up or down based on demand.
- Ensure high availability and fault tolerance of the data ingestion and processing services.
Sample Solution - AWS Based Data Processing Architecture (Draft)
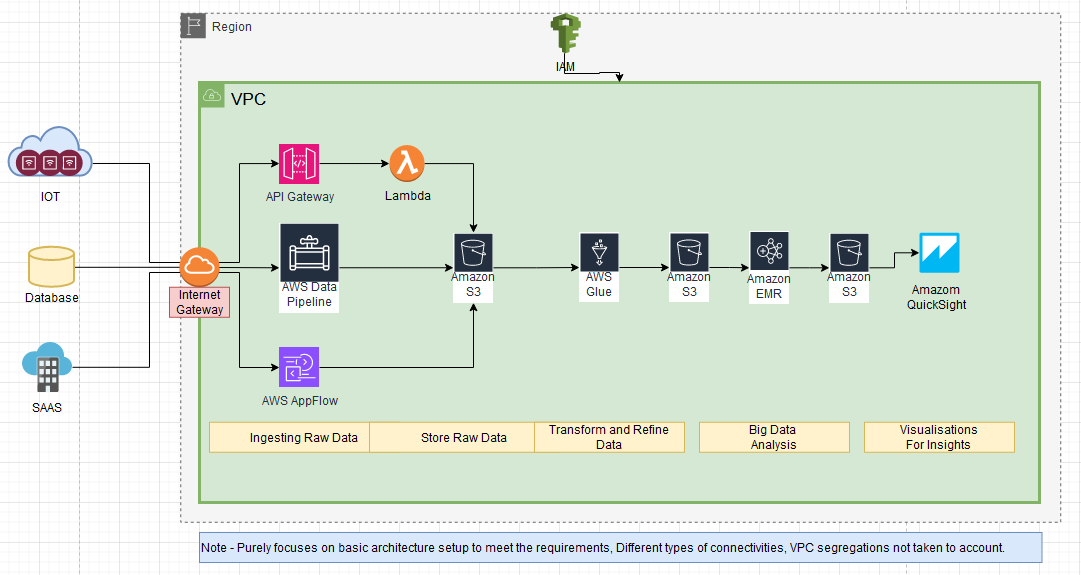
AWS Services Utilized
- API Gateway → Lambda
- AWS Data Pipeline → Amazon S3
- AWS AppFlow
- AWS Glue
- Amazon EMR
- Amazon QuickSight
Data Processing Stages
- Ingesting Raw Data
- Store Raw Data
- Transform and Refine Data
- Big Data Analysis
- Visualisations for Insights