Quick takeaways:
- Summarises the generative AI request lifecycle from prompt ingestion to response delivery.
- Breaks down transformer components such as tokenisation, embeddings, attention, and decoding.
- Flags additional operational considerations for optimisation, safety, and deployment strategies.
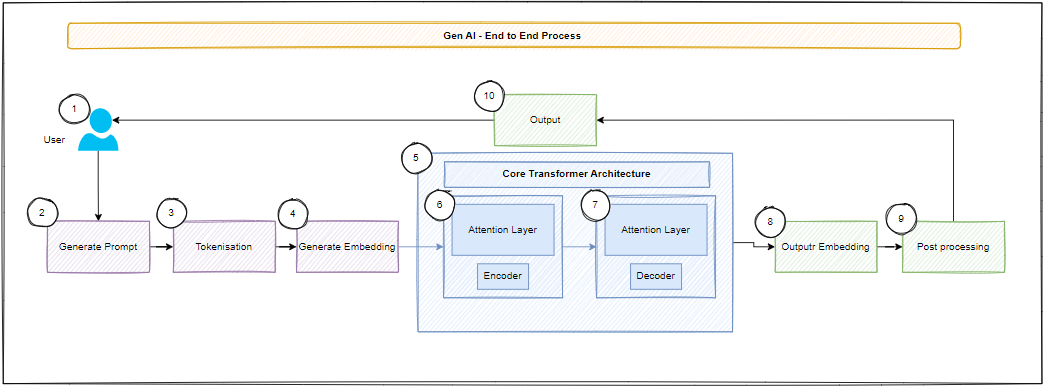
The journey below follows a typical interaction that a user initiates with a generative AI experience. It highlights the artefacts required to deliver value, as well as the checkpoints that keep responses safe and contextualised.
Core Interaction Loop
- User: The process begins with the user, who initiates the AI interaction. This usually happens over a chatbot console like ChatGPT.
- Generate Prompt: The user prepares a prompt or instruction the AI should respond to. Prompts are written in natural language and can include content, tone, or format guidance.
- Pre-Processing: Before tokenisation, the prompt may be inspected or enriched. Typical steps include redacting sensitive values, applying guardrails, or augmenting with contextual data.
- Tokenisation: The input is tokenised into manageable pieces such as words or sub-words so the model can understand and process it efficiently.
- Generate Embedding: Tokens are converted into vector representations (embeddings) that capture semantic meaning and relational context.
- Positional Encoding: The embeddings receive positional encodings so the model can reason about token ordering. This step is part of the managed AI Experiance.
- Core Transformer Architecture: Embeddings flow through the core Transformer made up of encoder and decoder stacks that iteratively refine understanding.
- Attention Layers: Self and cross attention mechanisms allow the model to focus on relevant parts of the input and previously generated output.
- Feed-Forward Networks: Dense layers inside each block further transform signals to capture higher-order relationships.
- Multi-Head Attention: Multiple attention heads run in parallel so the model can capture different patterns and relationships simultaneously.
- Decoder Attention: Decoder-side attention helps sequence generation by aligning with both the encoded context and the tokens already produced.
- Output Embedding: The decoder's output is projected back into token space through an output embedding layer.
- Softmax Layer: A softmax layer converts the logits into probabilities for the next token candidates.
- Post-Processing: Generated text can be normalised, checked for safety, or augmented with formatting before delivery.
- Output: The polished response is returned to the user interface.
Additional Considerations
- Layer Normalisation & Residual Connections: These architectural enhancements enable the training of deep networks by stabilising gradients.
- Training Process: Model parameters are learned from large training datasets and refined through fine-tuning or reinforcement learning.
- Parameter Optimisation: Optimisers minimise loss functions so the model can adapt to desired behaviour.
- Loss Calculation: Loss metrics quantify the difference between predictions and ground-truth outputs during training.
- Decoding Strategies: Techniques such as beam search, nucleus sampling, or temperature scaling influence how the model selects the next tokens.
- Hyperparameters: Model depth, embedding sizes, and other hyperparameters must be tuned for the problem space.